



 2020-11-23
in
2020-11-23
in

 4 min read
4 min read
As I wrote in this previous post I’m doing a series of benchmarks of .NET and JVM on Apple Silicon. While there are impressive native benchmarks the fact it will be some time before these two runtimes natively support it we have to factor in the potential hit and problems with Rosetta. How much of a performance hit is there and will it be enough that applications targeting it will have problems? All code and results are published here . For the first benchmark we are going to explore the performance of JavaFX.
For this benchmark I started with FXBenchmark01 project by Michael Hoffer whom based it on the Bubblemark benchmark. While it was a good starting point I did end up making some modifications for my purposes. I cleared out a bunch of the Swing and some other code not central to the JavaFX part of the benchmark. I also added some command line options to allow me to reconfigure it without recompiling. The original benchmark didn’t seem to resize the ball travel area when the window resized. My code does that. My code also tweaked some of the scaling and time measuring. Specifically for very slow runs it was possible to have artifical truncation of the framerate. When it’s executing it looks something like this (although with far more balls):
JavaFX Bouncy Balls Benchmark
This isn’t the most complicated test in the world, but it’s similar to the “Dope Test” .NET graphics test people use for benchmarking the number of operations per second. Instead of benchmarking operations per second I’ll be benchmarking the framerate. JavaFX intentionally forces the framerate to 60 fps. It used to have a setting for letting it go as fast as possible but that seems to be removed in the latest versions we are compiling against. So instead I’m cranking up the number of balls to obscene proportions, up to 100,000, to see the effect on frame rate. This will test a combination of rendering and the raw performance of the JVM in moving the balls but the actual busy work is all in the drawing code itself. With 100,000 balls the code that simply updates the ball motion can still loop 1500 times per second, according to the benchmark code.
One thing I was concerned about was the potential for the actual window size to affect the performance as well so the original tests started with a small window and then incremented it up gradually. In these tests, on all platforms, the difference from window size is pretty negligible. Below are two plots showing the frame rate changes as the number of balls increases. The first shows the whole range and the second shows it zoomed in to 50,000 balls or more range. As you can see the difference with window size is not too profound. For that reason when we compare platforms we will only be looking at the largest window size only.
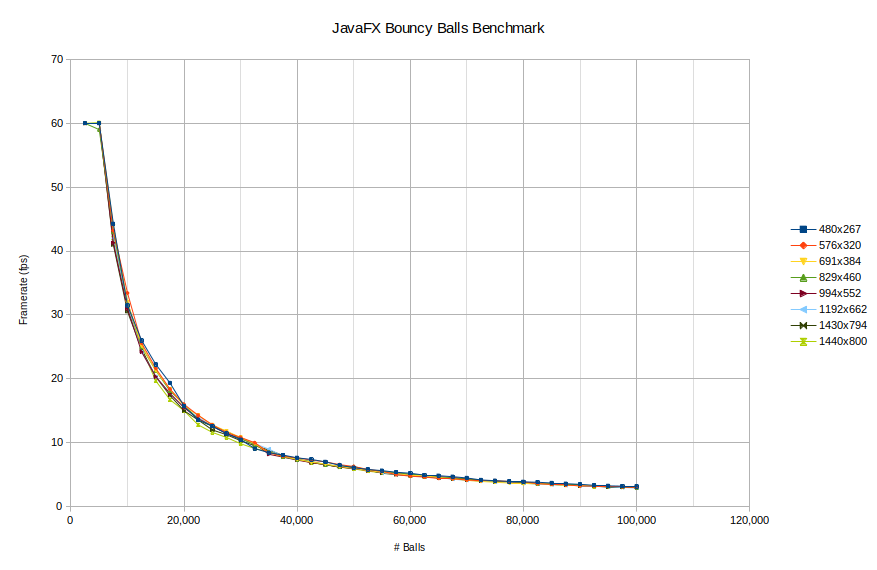
Framerate as a function of #balls and window size is essentially the same
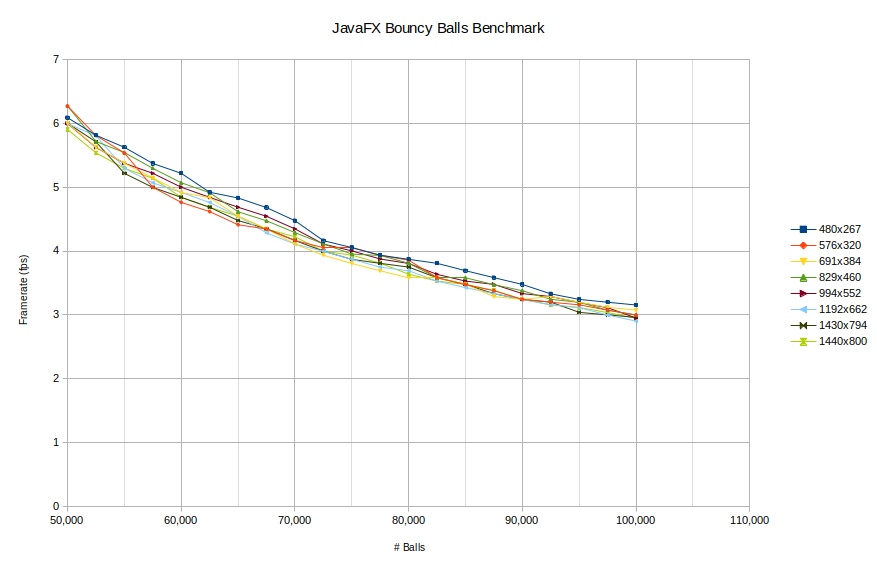
Framerate as a function of #balls and window size is essentially the same
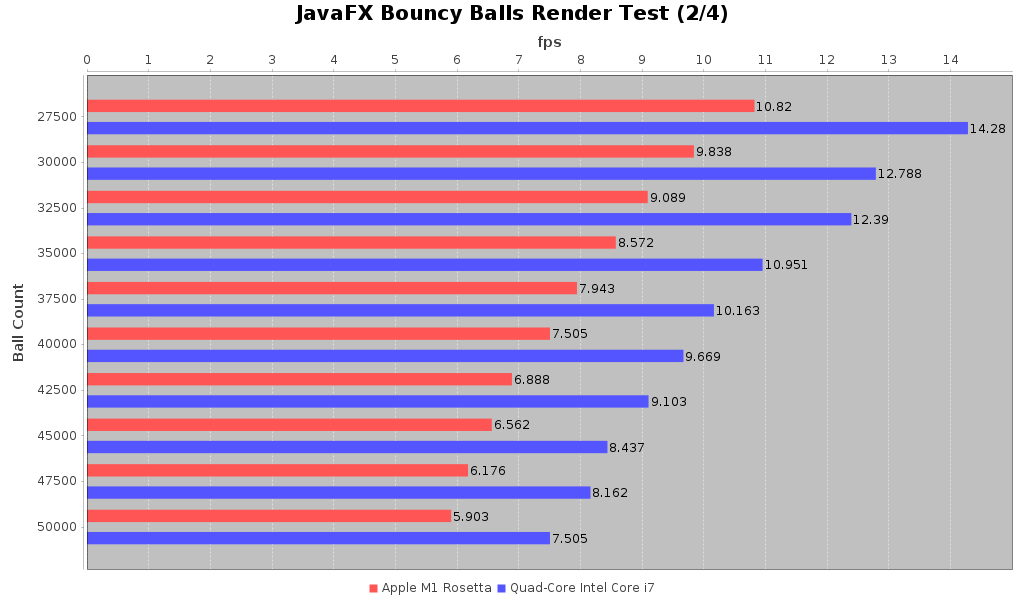
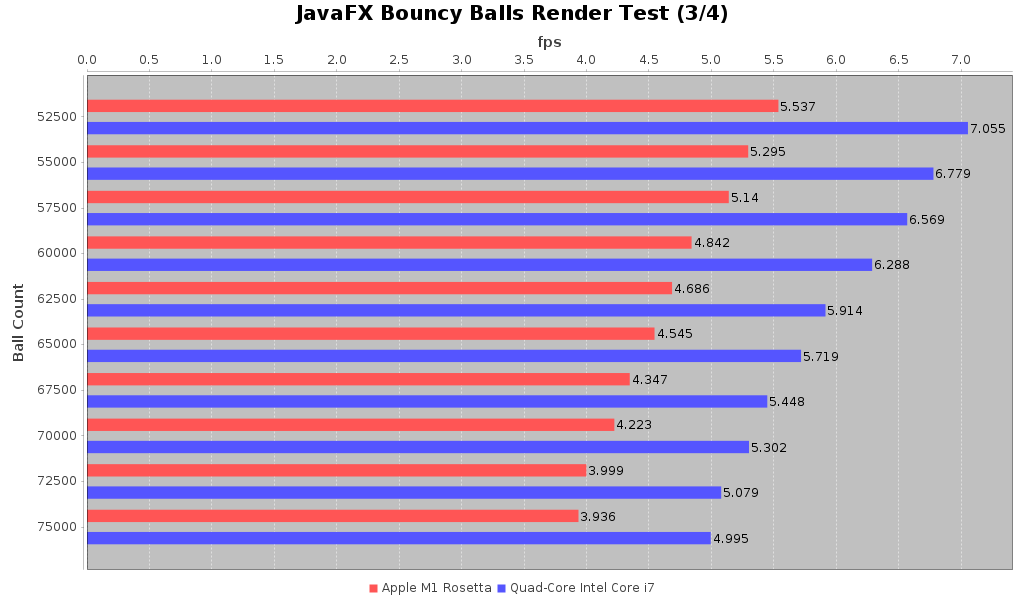
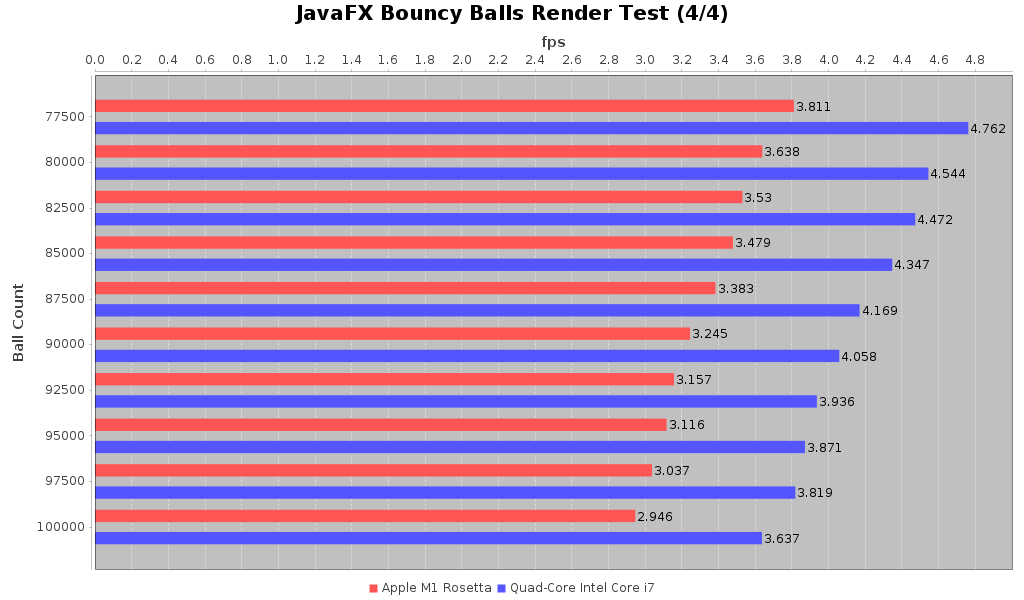
So with that lets look at the comparison of the 2018 Intel MacBook Pro against the 2020 M1 MacBook Pro with the JVM running under Rosetta. The full suite with tabular data can be found here
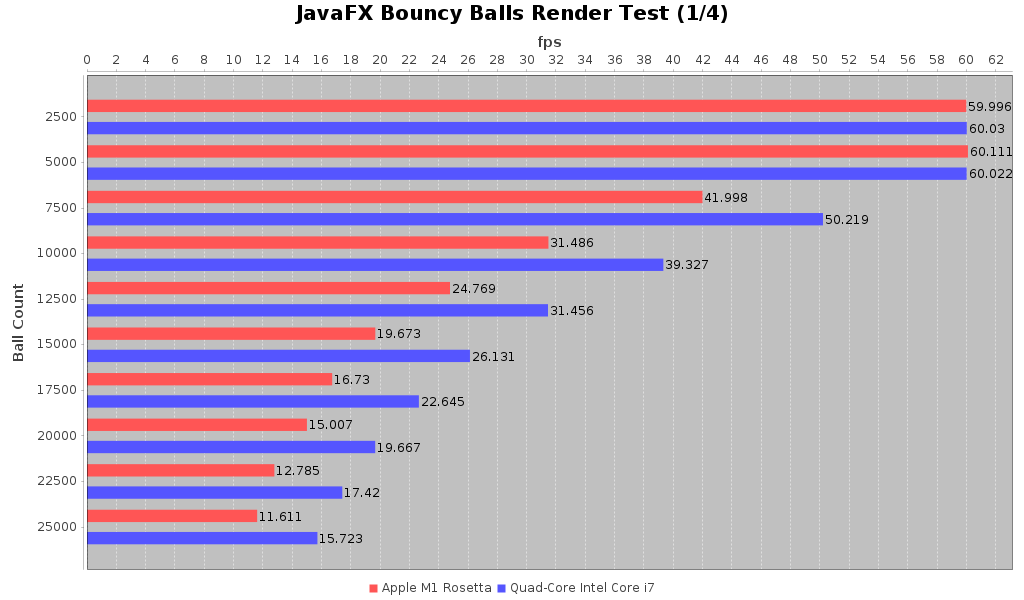
Framerate Comparison Chart #1
Framerate Comparison Chart #3
Framerate Comparison Chart #3
Framerate Comparison Chart #4
As we can see there is a consistent performance hit for the M1 under Rosetta over the 2018 Intel MacBook Pro. It comes out to be about 75-80% of the frame rate that one can get on the older Intel machine. That’s not great but it’s not catastrophic either. I don’t think that the JavaFX code is doing much with GPU optimizations. When we review the Uno Dope Test benchmarks you’ll see why I said that.
So for the first result, we see that the JVM running on Apple Silicon M1 under Rosetta performs about 75-80% of the same test run on a 2018 Intel MacBook Pro. As someone who has been using IntelliJ on my M1 MBP I have to say it may feel slightly more sluggish than on my 2018 MBP but I it’s not noticeable enough for me to say it is definitely noticeably slower.
If anyone would like to run the benchmarks and contribute results for other Intel or Apple Silicon Macs I’d be happy to take contributions. Please reach out to me via email (hankgrabowski@gmail.com ) or social media direct messaging on one of my listed active accounts.