



 2020-11-24
in
2020-11-24
in

 3 min read
3 min read
For the second benchmark I am going to explore the performance of Java with a library I use on a regular basis for astrodynamics calculations: Orekit . There has been a change since I started this (see this previous post ) though. Azul , a company that specializes in Java and JVM infrastructure, has released a version of OpenJDK that is compiled for Apple Silicon. I have therefore run the benchmarks both using AdoptJDK Intel installation running under Rosetta as well as the Apple Silicon Native M1 one by Azul. Let’s see how Orekit runs in these three environments. The full project and results is documented here .
The “tests” I’m performing here are to simply do a clean checkout and compilation of the Orekit library and then to also run the shipping test suite that comes with it. I use the time command to time a warmed up clean install (e.g. all dependencies have already been pulled down off the internet). I then separately use the time command running the tests separately. The test output is recorded to a log file. The test system which is used outputs timings for each of the unit tests. From these I can build up aggregated compile and test times as well as to get a detailed comparison of every single test’s performance. The story is pretty astounding. Let’s look at the top line summary data (dataset with tabular numbers can be found here
):
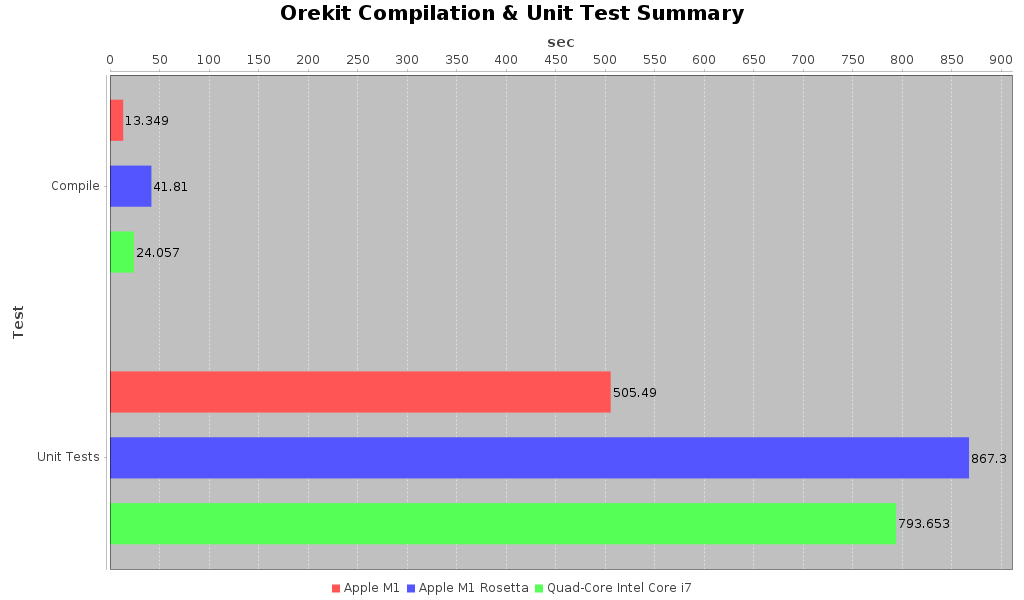
Orekit Compilation and Test Summaries
When I only had Rosetta results I was looking at this in terms of how much of a slow-up would I consider acceptable. In compilation performance it took nearly 1.7 times as long to compile the package under Rosetta as it did on the native intel machine. While compilation performance was definitely a dog the actual runtime performance wasn’t too bad. The tests only took 10% longer to run under Rosetta as it did on the native Intel MBP. So that was a pretty solid performance but the long compile times were a bit worrying. The story changes radically under a native JVM though.
The compilation time for the library on the native VM is almost 2 times faster (1.8 times). That’s very impressive. The execution time for the tests also registered an impressive more than 1.5 times faster as well (1.57 to be precise). Even in my optimistic assessment for how fast things would run I wasn’t expecting that.
The detailed results of the unit tests can be found here . As you can see the story is pretty much the same. With the exception of a few benchmarks the JVM running under Rosetta clocked in slower than the native Intel chip. Sometimes it was just a 10 percent difference, and on a few tests it was even faster. However on several the performance difference could be 2x slower or worse. That’s not so great. However the native JVM performance similarly is consistently better than native Intel, sometimes more than 2.5 times faster! there are literally over 500 tests you can delve through at the above link if you’d like to explore more.
The bottom line is that while Java code under Rosetta would be adequate it is practically screaming compared to the Intel MBP when run in native mode. All of these tests are single core computations. I have another set of benchmarks to test multi-core computation performance. Still with these results alone I’d say that these are way faster if you decide to run the native OpenJDK from Azul. Right now I don’t see a downside to doing that.