




 2022-06-07
in
2022-06-07
in

 10 min read
10 min read
As a part of leaving Twitter I decided to write a script that would delete all of my Tweets, Retweets, Likes, and Follows. The idea was that when it was done I would again have a bare profile. First I downloaded my archive. In it were over 1500 follows, 20,000 tweets, and 95,000 likes. Due to rate limits placed on the Twitter API by Twitter it is only possible to go through 200 delete operations per hour. Therefore deleting all that data would take over three weeks. That is why I was shocked to see that the operation completed in about two days. The more I dug into what was happening the more I saw how amiss things were with Twitter’s data consistency.
What Is Eventual Consistency?
Most non-programmers assume that when something gets done on a site like Twitter everything happens instantaneously. Your Tweet goes up, or is deleted, as soon as you hit “Send” and your own app/browser refreshes. Therefore everyone on the planet would be able to see that data too. For systems as large as these though this isn’t how the system works at all. That one change was committed nearly-instantly to whichever particular server you happen to be communicating with. That change then has to propagated to the various different data stores on that server and to other servers throughout the network as well. Eventually, ideally over a few seconds or minutes, the view presented to everyone on the network is consistent. This is done for scalability purposes. You can’t have networks this large operating out of one server. You therefore have do distribute it throughout thousands of servers. You don’t want to have a single point of failure and also don’t want to have users from the other side of the planet trying to get data from a server. You therefore distribute the servers around the world and try to have users connect to relatively local ones. So that one piece of data gets committed to that one server instantaneously but then the rest of the ones throughout the world have to catch up. You don’t want the user to be stuck looking at a spinning beachball, hourglass, or whatever waiting for all of the data to get to all the servers. Eventually it will, and that’s what we need. I expected some of this sort of behavior with Twitter. It is far worse than that though.
What Eventual Conistency Should Look Like
I have three views into the data in my Twitter account: the Twitter API, the Twitter website, and my Twitter Archive. While things are in flux you would expect there to be divergence between these three, especially the archive since it is generated at a particular point in time. However the data I get back across them is not consistent with respect to my Tweets and Likes.
The original design of my Twitter Shredder Command Line Application calls into the the Twitter API to get a list of Tweets/Retweets/Replies (called statuses in the API) and/or Likes (called favorites). That call returns the most recent of each of the respective Tweets that correspond to the request. From that list I get their IDs and then call into another part of the API that lets me delete those elements. In early testing this all seemed to work consistently well. It would pull a few of the most recent Tweets/Likes. I’d watch it delete them. Shortly thereafter they would disappear from the Twitter website. The only hiccup in all of that were cases where there were media attachments. The “Media” tab on the profile would show “Tweet Deleted By Author” warning cards like here:
After several hours even these error cards would go away and everything looked as expected. With that test done I then deployed it against my entire account. As I wrote above I did some quick math and determined that it would take over 24 days for all of the deletes to happen due to rate limiting on the Twitter API. When it showed up as done two days I figured it had an error and shut down. When I started it back up and it completed saying there were no Tweets or Likes to delete I thought perhaps I had missed something so went to check the website. That’s where the problems begin.
When Is A Tweet Not A Tweet?
At this point when I go to the website I should expect to see a profile with nothing on any of the “Tweets”, “Tweets & replies”, “Media”, and “Likes” tabs on my profile. The first two were clean. The Media tab had the aformentioned warning cards which now don’t appear to ever go away. The “Likes” tab however had something else going on. First let me show you what the list should look like. Below are the three most recent things I’ve liked for demonstration purposes of this post:
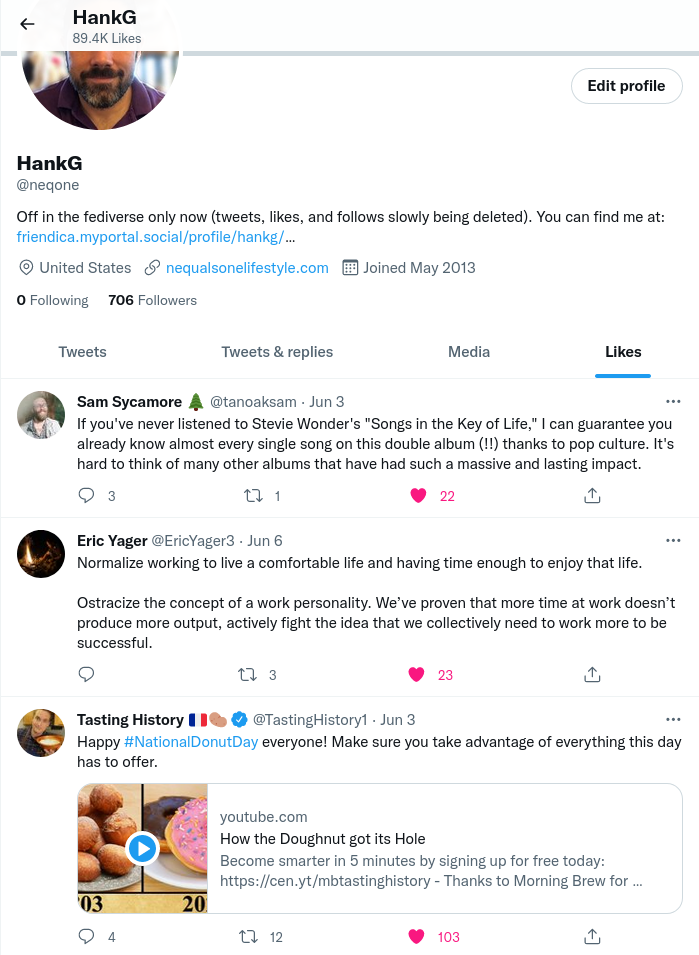
As you can see each of them has a filled in heart, which is what indicates that you have “liked” a Tweet. So far so good. However what I see after supposedly deleting all the likes is this:
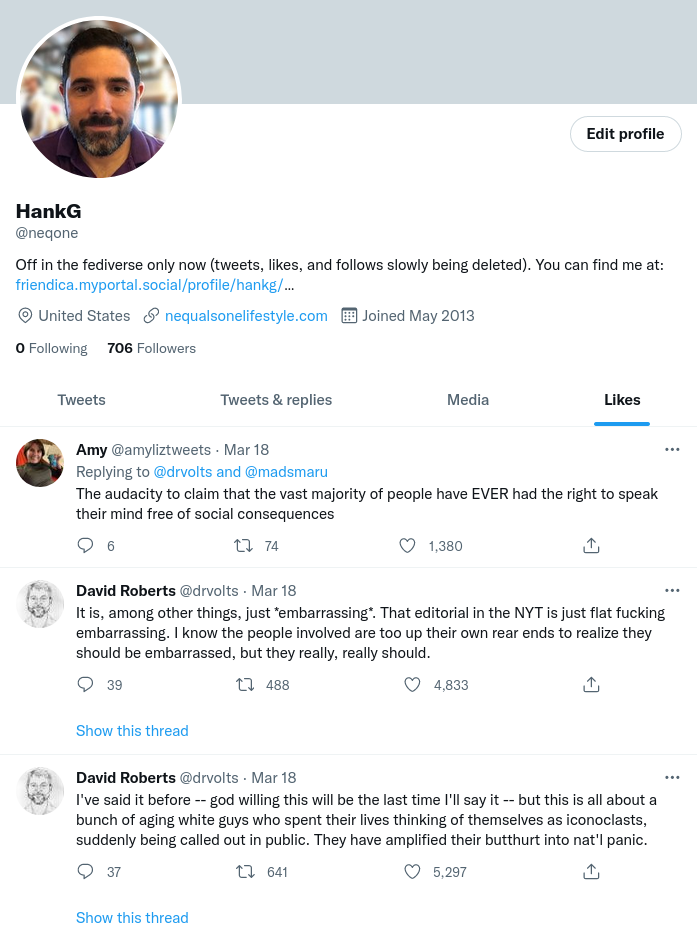
It may be a subtle difference but you’ll notice that the hearts are no longer filled in. In fact, scrolling down for many many pages none of them ever are. These half liked/not liked Tweets, whatever they are, in fact never show up in the Twitter API calls when I ask it to list the Likes. I therefore spent some time trying to investigate it assuming that I just had some sort of error in how I was calling the Likes API. I could manually delete the like by clicking on the heart to re-like it and then clicking on it again to unlike it. That would be tedious if there were a lot of these left.
While I was pursuing all of that something weird happened with my Tweets list. Suddenly a rogue Tweet appeared on the timeline. Again the API was returning no Tweets when I asked it to list them so I just manually deleted it and went on my way…until it happened again. It seemed every few days the profile view on my timeline a previously deleted Tweet would show up.
New Ground Truth Data
How do I confirm what is going on in all of this? Simple, I create another achive and see what is left behind. At this point according to the API and the website there were no more Tweets, Retweets, Replies, or Media. I knew there were many Likes but didn’t have any ability to get a number. Since the most recent ones were back in 2021 so I figured that was a good sign that many of them were deleted. The export done on May 29th was 1.5 GB. Since ostensibly all the Tweets were deleted most of the archive should no longer exist and it should be a lot smaller and thus faster to generate. Yet it again took another day to generate and came in at 1.2 GB. What the hell was going on? Did it have deleted Tweets in an archive or something like that?
Thankfully Twitter provides a convenient web page inside each archive that you can use to browse and search your exported data. I have to give them hats off to that. All of the archive viewers I have had to write for the Fediverse and Facebook are unnecessary for Twitter data. It told the story about how much delete was actually removed:
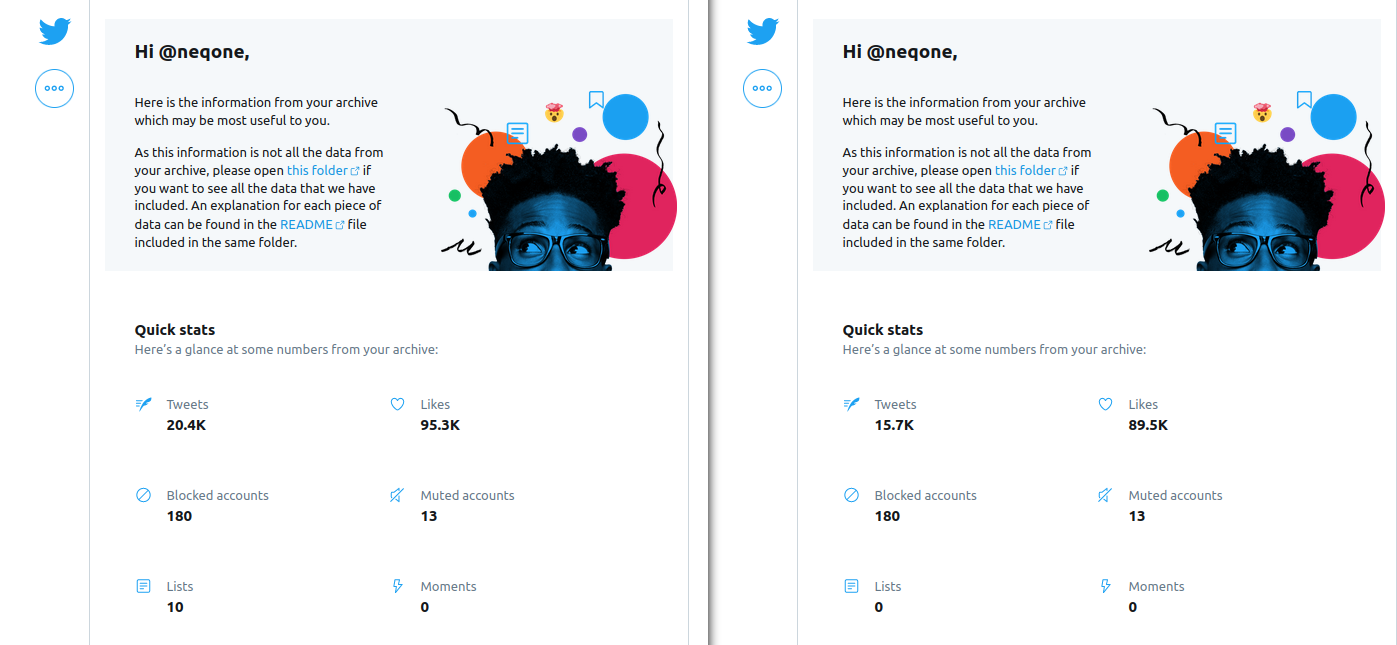
Now I’m starting to grow concerned about how well my original methodology would work based on the performance of the Twitter API itself. While the API endpoint that lists Tweets, Retweets, Replies, and Likes all show that none exist I see that there are still over 15,000 Tweets/Retweets/Replies and over 89,000 likes still in my account. The likes are directly visible on my profile page but the Tweets etc. are not. Are they visible at all?
Here is where even more consistency issues come about. First, I’ve already seen some random Tweet pop up in my profile from time to time. I don’t know what causes that to happen but it has happened more than once. Second, the archive has a link to the URL for the tweet. If I click on that for my own content it always goes to a page that can render my Tweet. Therefore someone who goes to my page doesn’t see it exists but it shows up when viewed directly. It also shows up on other people’s timelines if they liked, retweeted, or replied to it. That’s a problem. A bigger data consistency problem exists for the “Likes” though. I had assumed that perhaps the incorrectly marked “likes” (the ones without a filled in heart) wouldn’t show up in the archive. They did show up in the archive though. I therefore assumed that perhaps all of them would render in the browser without the heart. Unfortunately sometimes they do render and sometimes they don’t. So I’m stuck with this mostly undeleted state of affairs. But it gets a bit worse than that
Twitter v1 API Design Problems With Deleting Likes
The API for deleting a “Like” is the same for deleting a Tweet/Retweet/Reply. You provide it with the ID of the original Tweet that you liked and/or want to unlike. Here is the Likes delete endpoint documentation showing all the options. It all boils down to a simple call to a URL like this:
POST https://api.twitter.com/1.1/favorites/destroy.json?id=1050118621198921728
Which in this case would delete a Like that the logged in user has for this tweet if it exists. That’s pretty straight forward. What happens if you try to delete a Like on a Tweet that you haven’t liked? You get a 404 error. That kind of makes sense. What happens if you try to delete a like on a Tweet that you can no longer see because the user made it private, stopped following you, etc.? It still shows up in the list of likes but since you aren’t allowed to see with/interact with that Tweet the response from the API is also a 404 error. Therefore that Like can never be deleted from your account through the API. Did the new API fix this? I’m not sure. Since the state in the UI seems to also be messed up in terms of being able to get to it I’m thinking the answer will be “no”.
Problem Identification and Solution
There are two main problems that I’m encountering. First, the states across the three presentations of the Twitter account is not consistent. The closest to ground truth that exists is the exported archive itself. The Twitter API is the worst of these. I thought that perhaps the problem was that the gap between “now” and the first Tweet was too great and therefore needed a better “initial guess”. I tested it where I explicitly listed the “maxId” to be one greater than the most recent tweet still in the archive. It still didn’t return a value. The problem is therefore that the listing APIs can’t be relied on to be returning good data. Fortunately the delete operations when given the correct ID does work.
What is the solution then? First, I need to stop using the listing APIs to get tweets back to delete. Instead I need to point the tool to the user’s unzipped archive folder and crack open the respective JSON files to get the list of Tweets and Likes. Then I can pick up where I left off. However this type of flow requires some tracking on my side. In the original flow it asked the Twitter API for the most recent items and then went about deleting them. In the new flow if it doesn’t keep track of previously attempted deletions then it would have to start from the beginning again. If there were bulk deletes and the whole operation would takes minutes or maybe even hours it would be no big deal to do the extra work. However starting over on a 24 day operation is insane. Some semblence of tracking of previous attempts needs to be added as well.
Therefore my simple one file Twitter Shredder is now going to have to get a bit more complicated to handle reading from an archive instead of an API and keeping a history of deletion attempts.