



 2022-02-11
in
2022-02-11
in

 11 min read
11 min read
I’ve written previously about Dart performance benchmarking (smallest/fastest program stats and DeltaBlue benchmark against JavaScript, Java, and C ). Because of a quirk of fate this week I embarked on studying the performance of all of the current maintained HTTP service libraries available for Dart server side development. This will be followed shortly with how that compares to Go which was the original basis for this study. The code and data can be found in this Gitlab repo .
The Frameworks
Below is a list of the frameworks that were studied and a brief description. This analysis is strictly looking at performance of a single endpoint REST server and not a study of performance in a larger scale, ease of use, feature set comparison etc. Nevertheless I am presenting a brief amount of information on these other topics for context.
Original http_server (Hypothetically discontinued)
The original HTTP Server
for Dart is a part of the core dart:io library that you get with your standard imports. Unfortunately in the last year or so it has been discontinued. The idea behind this component was to provide a simple bare bones HTTP Server functionality in the language. With it one can build some pretty decent applications but it was never meant to be a full service REST framework. While it is considered discontinued it is still part of the core library. I don’t know when/if there are plans to excise it though.
Shelf
Shelf
is considered the heir to the http_server parts of dart:io. It too is supposed to be an easy and light way of building REST services but it does have a lot more features than the original http_server library. It supports a more scalable means of building up handlers, routers, and components that one needs for more than trivial API implementations.
Alfred
Alfred is approaching the concept of being an HTTP middleware library from the same perspective as Shelf. Unlike shelf it is attempting to be architecturally homologous to ExpressJS . What I mean by that are that things like the handler syntax will match ExpressJS to a certain extent. Like Shelf though it is strictly looking at being the library for the REST service outward facing code, unlike our next two which are full stack service libraries. It explicitly has limiting itself to being just this part of the stack as its design goal, again in the spirit of ExpressJS.
Jaguar
Jaguar bills itself as a “full stack server framework with MVC, ORM, Serialization, Auth, and Security” built in. Being the library for writing your REST endpoints is only part of it. It attempts to be the one stop shop for how you interact with your database, how you can build more complex services with controllers, how to create UIs with server side templates, and more. It would hypothetically be your one stop shop for building a web service.
Conduit
Conduit is another full stack web services framework like Jaguar. It is actually a fork of a previous project called Aqueduct which was discontinued about a year ago. Like Jaguar it is trying to be a soup to nuts web services framework having a built in ORM, authentication support, etc. Unlike all of the other frameworks listed it is also built to support multiprocessing capability out of the box. The Alfred project has some code to show how one could conceptually create a multiprocessing version. Under the hood it is probably doing something akin to what Conduit is doing. Conduit however has a whole run architecture designed around being able to manage concurrent processing. As a downside to this, and the use of the dart:mirror library, Conduit must be run with a full Dart stack and through the Just-In-Time (JIT) compiler.
Goals and Methodology
The main purposes of this study are to determine:
- If there are substantial differences between the various frameworks in the simplest case
- The maximum throughput of a Dart REST server is with existing frameworks
- Any failure modes with a server under stress
The main points of the technique used to determine this are:
- Write a simple REST server in each framework with one route to the root path
/ - At run time one of two versions of the REST service will be injected. One version produces a static string
Hello World!which will be served back. The second will dynamically build a string based on the current time formatted as an ISO/RFC string. - Using wrk HTTP benchmarking tool for stress testing each server and generate statistics about the response over a given interval (for the current data set a 60 second run)
- Work is configured to simulate 1000 users using 4 system threads and execute against the root endpoint for 60 seconds total.
- To make the process as clean as possible the wrk tool and Dart servers were run on their own separate machine instances in Digital Ocean. Both instances were hosted out of the same data center with communications being done through their public IP addresses. The stimulation machine had 8 dedicated vCPUs. The server machine had 8 dedicated vCPUs for most tests but for scaling tests had up to 40 dedicated vCPUs. The tests never saturated the CPU or memory of the driver machine.
- The code implementation for each is attempted to be as similar as possible to give no one implementation an advantage. Below are code snippets for each of the implementations
- Because we saw differences in Ahead-Of-Time (AOT) style deployment (building into a self contained executable) and JIT style deployment (running from the
dartcommand) in the DeltaBlue Benchmark Study we are running each test in both AOT and JIT mode. The exception to this are the Conduit cases since it cannot be compiled with the AOT due to itsdart:mirrordependency. - Because Conduit needs to be run in its own runner the code to get access to concurrency features it is hosted both in the unified
dartserverapplication as the rest and also a Conduit-only version in the statistics.
http_server Implementation
HttpServer.bind(address, port).then((server) {
server.listen(staticResponse
? (HttpRequest request) {
request.response.write('Hello World!\n');
request.response.close();
}
: (HttpRequest request) {
request.response
.write('The time is ${DateTime.now().toIso8601String()}\n');
request.response.close();
});
});
Shelf Implementation
var handler = const shelf.Pipeline().addHandler(staticResponse
? (request) => shelf.Response.ok('Hello World!\n')
: (request) => shelf.Response.ok(
'The time is ${DateTime.now().toIso8601String()}\n'));
var server = await shelf_io.serve(handler, address, port);
Alfred Implementation
final server = Alfred(logLevel: LogType.error);
server.get(
'/',
staticResponse
? (req, res) => 'Hello World\n'
: (req, res) => 'The time is ${DateTime.now().toIso8601String()}\n');
await server.listen(port, address);
Jaguar Implementation
final server = Jaguar();
server.get(
'/',
staticResponse
? (context) => 'Hello World\n'
: (context) => 'The time is ${DateTime.now().toIso8601String()}\n');
await server.serve();
Conduit Implementation
final app = conduit.Application<BenchmarkChannel>()
..options.address = address
..options.port = port;
await app.startOnCurrentIsolate();
Where the BenchmarkChannel implementation was:
class BenchmarkChannel extends conduit.ApplicationChannel {
@override
conduit.Controller get entryPoint {
final router = conduit.Router();
router.route("/").linkFunction(staticResponse
? (request) async => conduit.Response.ok('Hello World!\n')
: (request) async => conduit.Response.ok(
'The time is ${DateTime.now().toIso8601String()}\n'));
return router;
}
}
Results
Along with the below results description you can find the raw results and spreadsheet in the project’s Gitlab repo . Let’s first take a look at the throughput numbers. Throughput was measured over regular intervals of the execution and reported out with statistical information at the end of the run. We therefore have the average, standard deviation, and maximum throughput of each of our configurations.
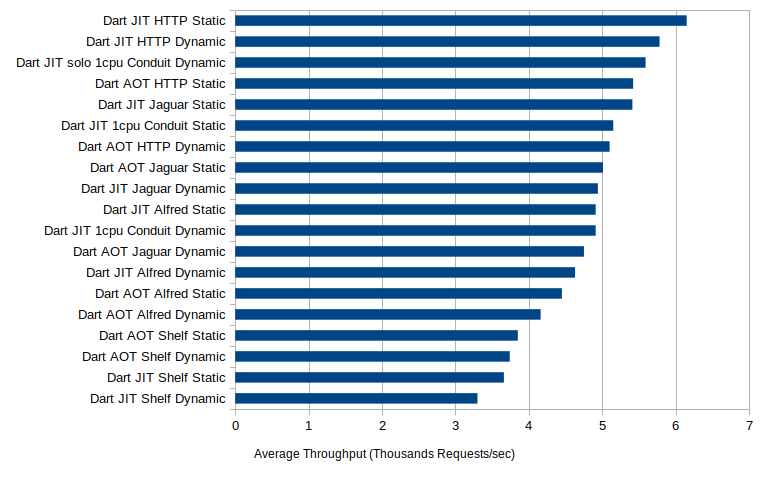
Looking at the averages alone we can see that the single CPU cases can serve up between 3300 and over 6000 requests per second. While there is some small but noticeable differences between the dynamic and static cases we don’t have anything like a factor of two difference between them, on the order of but less than 5-10%. This is on the same order of magnitude difference as we see between AOT and JIT compiled versions of each test suite. While for the most part the JIT compiled versions are faster in the case of Shelf the opposite is true, and dramatically so in the dynamic run case. In terms of throughput by far the top performer is the discontinued http_server library and Conduit, with Jaguar and Alfred picking up the middle. By far the worst performer, and consistently so was Shelf. Considering that Shelf is supposed to be the new default “standard”, at least for standard documentation etc, I’m pretty surprised at its performance. When we look at the performance for Conduit when we let it use multiple processors, the only framework that can out of the box, we see dramatically improved throughput.

These tests were run initially on the original 8 core server configuration being allowed to use all 8 cores. A follow-on test was executed on a 40 core server being able to use all 40 cores. As we can see there is dramatic improvement in both of these execution cases, with the 8 core system clocking in over 18,000 requests per second, and the 40 core one over 38,000. While it was possible to saturate the 8 core system, CPU wise, it was not possible to do so. It was using on average about 10-12 CPUs worth of processing power during the run. We could at that point be limited by network issues rather than processing though. Beyond sheer throughput we also need to look at the latency of the requests:
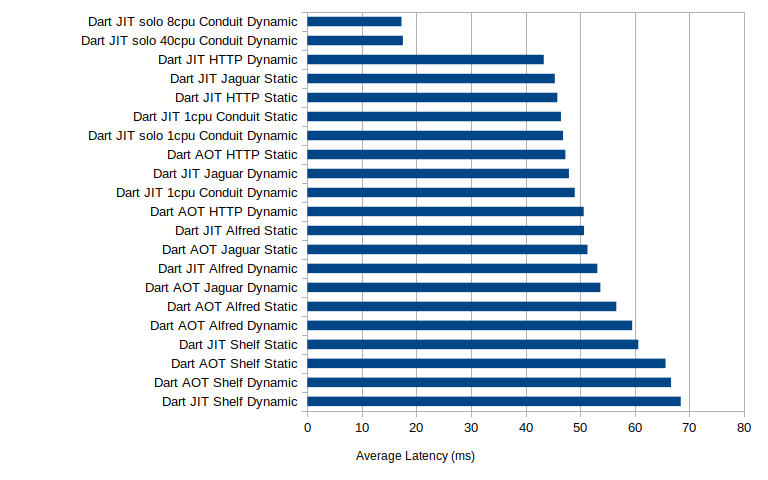
Again there is a pretty wide dispersal here, even if we just look solely at the single core cases. The per-request latency for single core is between 43 and 68 milliseconds. Again there is a pattern though where JIT often outperforms the AOT version of the run but the difference between static and dynamic performance is more of a mixed bag, sometimes dynamic is faster sometimes static is. In my mind that means these latencies are mostly dominated by steps between the server and response generator not the response generator itself. Once we add the extra CPUs the latency drops dramatically as it can start concurrently processing requests. The latency of the multi-core Conduit is a third the single core version and by far the fastest, although we didn’t gain much in latency response by throwing the additional 32 cores at it. All of this translates into some pretty expected total request counts over the run:
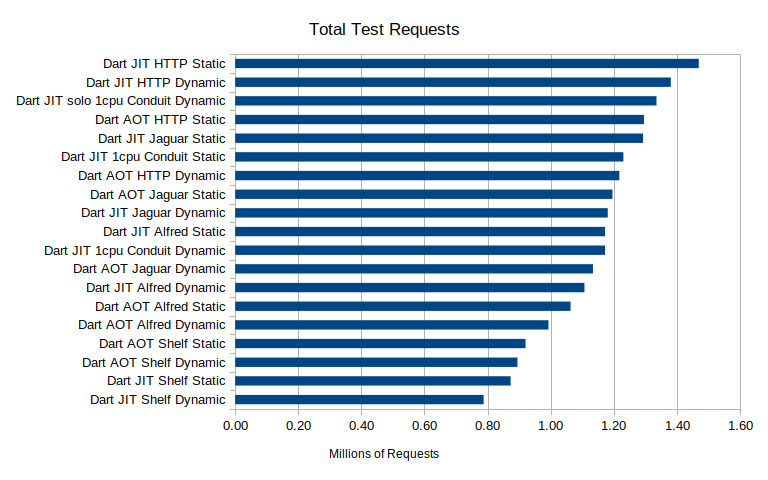
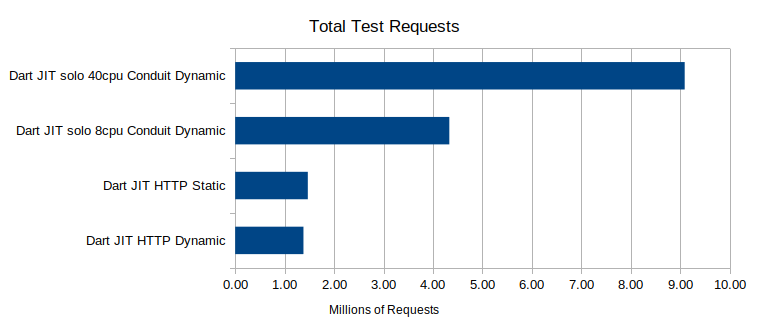
By far the best performing server was the discontinued http_server library followed closely by Conduit and Jaguar. Alfred is in the mix in the middle of the pack again. Bringing up the rear, and by a lot, is Shelf again. When we expand this to look at the multi-core cases we can see that we have dramatic increases in total requests by throwing more cores at the server running Conduit. If we had faster network interfaces, or more driver servers, I wonder if we could have gotten even more throughput out of the multi-core test. Each case though processed 800,000 to 1.5 million requests. Some of those requests however did timeout at 2 seconds response time though:
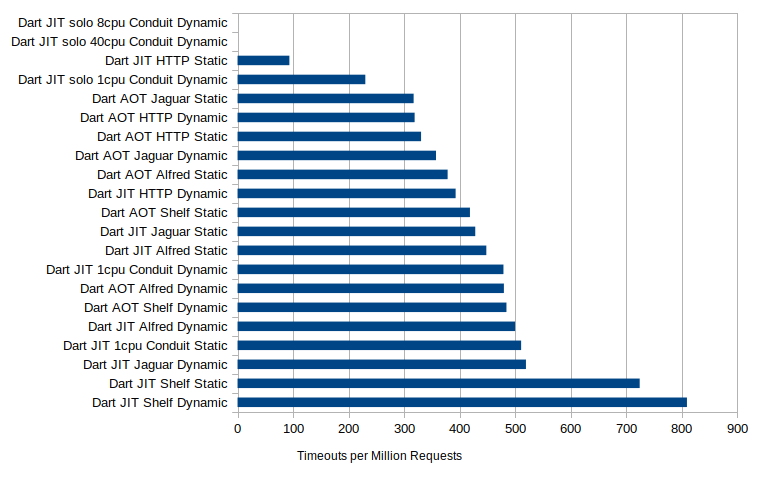
As we can see the multi-core Conduit cases had zero timeouts over their entire run. Every other case had at least some timeouts. Since they all processed different numbers of requests this has been normalized to the number of timeouts per million requests. Besides the stand out of the http_server JIT case and the two Shelf JIT cases, most of these are in the same band of a few hundred timeouts per million requests under load. For some reason the JIT version of shelf struggled far more than the other servers and I’m not sure why.
Conclusion
I posted previously about Dart performance and if it was acceptable for server side usage. I posted that notionally. This is the first look at using Dart for hosting a REST service with actual software even though just for the simplest service. We can see that even in the worst case scenario it was possible of taking a beating while cranking out 3000 to 6000 requests per second with just one CPU. If we use a framework that supports concurrency it can go up even further. This is far in excess of what most people’s servers will experience. My statement about the performance of Dart still stands.
I am confused about the poor performance of Shelf in this test though. Again this is the library that the main documentation is referring to as the http_server replacement. While it may help with composition it is pretty striking that it turns out the consistently worst performance of all of the frameworks. I get why http_server may have a leg up on it since Shelf is hypothetically targeting ease of use under more real world conditions and isn’t just about low level HTTP handling, but why is it that others with the same goal are able to outperform it so well. Why too is it the one language where the JIT slows it down rather than speeds it up?
Speaking of JIT vs AOT. It was interesting to see how much real world difference there was in this test case. In the DeltaBlue benchmark case the AOT performance relative to the JIT once the number of iterations cranked up was pretty stark. The loop time was 1.7 times longer as was total execution time. In this real world case the difference was noticeable and, with the exception of Shelf, always in the direction of the JIT being faster than AOT. However the difference in this case was more marginal, on the order of 10 percent not 70 percent.