



 2022-06-13
in
2022-06-13
in

 20 min read
20 min read
Back in the end of 2018 I wrote this first post in Jekyll after converting from WordPress . WordPress had started feeling too clunky for me and I always wanted to have something simpler. I looked at Jekyll and Hugo at the time. Back then the big bonus for Hugo was compilation speeds and it was supposedly a bit easier to get started with. The advantage of Jekyll flexibility and it being more seasoned, not that either were new. Because I was doing Ruby development at the time and Jekyll is written in Ruby I decided to go with it instead of Hugo. It served me pretty well for the past several years but with increasing compilation times and trouble getting Ruby Gems configured on my Mac I decided to take the plunge and try to convert to Hugo. I was not disappointed, which is why this article is the first post to the Hugo-built site.
Preamble
This is a total log and brain dump of my experience converting my blog from Jekyll to Hugo. It is a very long post to capture the entire conversion process for myself as much as for posterity of others. Use the table of contents to bounce around to the parts you feel may be more relevant to you.
Hugo vs. Jekyll
First lets look at the tools themselves. Both essentially take Markdown formatted text files, images, etc. and churn out a website that can be hosted by a static web server. That is as opposed to WordPress which often dynamically builds the website. There is a lot of syntax similarity for the post content in the Markdown itself but after that the similarities end.
Jekyll is built in Ruby. Around the core are a series of modules called Gems which are used to give it all of the standard functionality that one needs for a static site such as pagination, generating an RSS feed, etc. This gives it a lot of flexibility. Hugo on the other hand is written in Go and is compiled into one single executabe with everything you need (hopefully) inside it. That limits the flexibility if you need it but it does make installation and updating far easier. It also makes getting started easier because there is one way to do things, the Hugo way, versus with Jekyll where the Gem you use for certain features defines how it is to be done. I believe that this is why I felt more comfortable with Hugo after a day than I have ever felt with Jekyll.
Along with being a bit easier to use it is also a lot faster. I knew about the speed differences when I first selected Jekyll over Hugo years ago. I don’t really care if my site takes 5 seconds instead of 1 second to compile. Over the years though the site compilation time has gone to 45-50 seconds. Hugo processing the same site with a comparable them does it in 5-6 seconds.
While both have importers from various sites to their new format. Hugo has a Jekyll importer among them. The opposite is not true. The Hugo importer got me 80% of the way there on my post content. I had some massaging to do, which is listed below, which was a death by a thousand cuts exercise. But in a day the whole thing was converted over and running it.
Overall I’m finding Hugo to be more intuitive. It’s not just the single executable installation. I’m also finding the syntax in their templates to be clearer as well. Even after years of using Jekyll I felt very timid tweaking a theme for the previous version of my blog. The way sites and themes are laid out and how the code exists within them just seems to be more intuitive in Hugo. I still have some things I need to get used to but between that and the speed I look back at this transition with no regrets as of now.
Initial Steps
The initial step in porting my blog started with learning how to use Hugo. The website has a Quick Start guide that takes you through building your first site and your first posts. Because the Hugo executable has commands for doing that it was all very straight forward. Selecting and installing a theme may be a bit cumbersome for people who aren’t familiar with Git and they could do some additional explaining on the mechanhics of what is going on there but it was very easy to get the whole thing started.
Once I had the basics down it was off to find a theme. As it turns out the Jekyll theme I modified was actually built from taking the Hugo theme hyde-hyde and making it work for Jekyll. It was therefore a natural start for what I’d use for my theme. I spent some time getting used to the theme and how to customize it, the menus, where posts are stored, how to configure social media icons etc. The whole time I was learning how Hugo works since that is a big part of how themes work. It did provide some guidance around that though. Lastly I tried doing a trial import to make sure that some semblence of it would survive. Fortunately it got most of it correct.
From there I started messing around with figuring out how I’d recreate parts of my old website. I love having an archive page that lists the entire history of the site. In the WordPress days it was one of those collapsible tree view page components that would be off to the sidebar somewhere. As long as it is easy to get to then I don’t care. I wanted something similar for browsing tags and categories. While Hugo out of the box creates the tags and categories lists I didn’t like how it presented them. I therefore went off looking for examples of how to do all three of those things in Hugo. Again it was a learning experience getting used to how to setup layout components but it only took me a couple hours to really master it. Lastly, in my searching for the various archiving and tools I ran across a blog post that showed how to build a search capability that is statically generated as well. I therefore played around with that as well.
With all of that done it was time to do the site transition for real.
Final Steps
First I identified all the things I wanted to change about the theme. I didn’t want it to be pulling files from a CDN. I wanted to change the social media icons for the sidebar. I wanted my old theme. Along with some other things I ultimately decided to make my own minor fork of the original theme. I’ll describe the details of that in another post, but with a concrete list I knew that what I wanted to do was easily achievable.
Next I ran the import again and created the site from the Jekyll site. I then pointed it to my fork of the theme. I then figured out how large a job I’d have for fixing the newly imported site. In Jekyll I had my own custom “Figure” command for rendering images with captions, proper sizing, links, etc. Hugo has a very comparable one build in that I could use as a basis for my own custom one, so I did. It still left the syntax difference across hundreds of images in all the posts. The code block syntax highlighting was also a bit wonky. I could either put every language ever used in the site in the configuration for the site or add it to each respective page. I decided to do the latter to save server requests for pages that don’t have it. Also Jekyll’s syntax highlighter would default to something more pleasant if no type was specified or it didn’t know the language identifier used. Hugo puts up something more ugly, partially because I’m using a JavaScript highlighter tool that looks better and allows for scrolling. Tables were another thing that were a bit wonky. I had mostly used raw HTML tables. Hugo by default doesn’t allow raw HTML. I found a way to go through and mark the specific areas as “unsafe” instead of the whole site.
With that identified I went about customizing the theme for the goals I was trying to achieve. I spent the first half of the day working on the template. The second half of the day was cleaning up the posts so they rendered correctly, and confirming that. By evening I was ready to test running a build pipeline directly to the server. That worked pretty much flawlessly. The one hiccup I ran into is that while Jekyll blows away the target publication folder, Hugo does not. Therefore I needed to tweak the deployment script to do that as well. With that done though I was able to confirm the whole thing worked soup to nuts and started deploying it regularly to a secondary site.
It was then important to confirm that links to the site were working consistently with the old site. In that way people who referenced my old blog pages wouldn’t end up with broken links. That looked good out of the box. I wanted to confirm that it was properly serving the respective files locally not from a CDN and that it wasn’t serving files extraneously. That looked good as well. Lastly I wanted to make sure it was rendering in the RSS reader appropriately. While a new subscription would, the file location was different: a more standard index.xml rather than the old feed.xml. I wasn’t able to get Hugo to write to both files so modified the deployment script to copy the file for old RSS subscriptions. Lastly, the RSS feed didn’t include categories by default. I was able to take the standard Hugo RSS template and tweak it to include those again.
With that the site was ready to go live.
Stumbling Blocks
What were my biggest stumbling blocks when trying to get all of this going? The biggest problem was getting code highlighing configured properly. Since a lot of my posts are software development related and have code samples this was important. Unfortunately the rendering was ugly. I assumed it was something in my theme’s configurations so I started changing around the colors in the SCSS files. Nothing changed in the presentation though, even after a restart of the demo server. Deleting caches etc. didn’t fix it. As it turns out the standard install of Hugo doesn’t have dynamic SCSS rebuilding. You need the extended version. I noticed “extended” Hugo when I did the downloads but wasn’t sure what it meant. Now I do. With a simple download I fixed it but I wasted a good half an hour or more dabbling with settings trying to see how my configuration was wrong rather than my installation.
Once I got that squared away and started experimenting with code highlighting code it still wouldn’t change anything. This was due to me over-reading into the lack of settings in the example site configuration and the existence of code highlighting codes in the SCSS files. The whole time these things were being set by theme variables either in the HighlightJS configuration and/or the Chroma configuration. HighlightJS is used for browsers that have JavaScript and for code blocks that have a known type. Chroma is used for everything else. Each have their own set of standard themes, which are configured with a simple variable in the configuration. Once I knew that the whole thing was easy. Then the last configuration issue I didn’t realize was that naming the types being used for highlighting is a requirement for HighlightJS not an option. This was different than the way the built-in processor works on Jekyll, which uses Pygment, and Hugo, which uses Chroma. I tried setting it at the site level for all types I ever use but that ends up bringing in all the HighlightJS files for every page rendered. It’s only several KB of data but it is several requests from the server. So I opted to make it a standard part of every file to list the languages. Lastly if I wanted HighlightJS to be used for any code blocks I needed to specify the language. In lots of places I just put the triple-backtick and no type. After spending an hour or two spinning my wheels on the configuration cleaning all that up took less than half that time, thankfully.
Another problem I had was that a lot of the page templates examples starts with the “main” or “content” section that is core to the page. None of those examples worked for me. It would always render blank screens. At first I wasn’t sure if I was copying them in wrong or putting them or calling them incorrectly. When I looked at the one example I did have of page templates they had the header and footer block in them as well. Once I add them to each it worked! Since none of the other examples I found have that I have to wonder if this is a problem with the original theme’s design. I may or may not address that later.
Once things were really humming and published to the real URL, albeit not announced yet, I started playing around with making sure that everything integrated well with the rest of the world. I triple checked that old links still worked. Hugo has a means for using link aliases as well, Jekyll may have this as well I’m not sure, so I was actually able to fix some permalink errors I had previously with the old “wrong” link available via the alias for anyone that linked against it. But unfortunately the OpenGraph data was missing any image data.
OpenGraph data is what gives you a link preview when you past a link into a social media site, email, etc. It goes to the URL you specified, pulls down the HTML page, and looks for specific fields marked with properties like “og:description” and “og:title” in the header. In Jekyll I had to add my OpenGraph data manually. In Hugo it does it for you automatically. Unfortunately it was looking for a properties called “images” either in the site configuration or on the article to populate that field. That wasn’t well documented. Once I added one to the configuration as the default and overrode the value in posts that had previews it all worked. It actually worked better than my Jekyll code because it supports multiple images.
Another set of problems I ran into was regarding the RSS feed. Again, Hugo supports this out of the box so didn’t have anything to do. An index.xml, a standard place for such a file, showed up and was populated correctly. When I looked at it in a feed reader however I noticed that the articles didn’t have site-tags in FreshRSS like other pages did. Those had category fields filled in, which the default RSS template in Hugo doesn’t do. Simply copying their template into my layouts folder and adding those fields for each tag everything “just worked” again. Now the problem was that the Jekyll site published RSS to feed.xml not index.xml. I prefer the more standard index now but I don’t want to break any old RSS subscribers. I thought I’d be able to write to both with some configuration but unfortunately the best I got was an either/or. I tried a custom type which mostly worked, except the links presented were broken relative links. I ended up having a post-deployment step server side that copies index.xml to feed.xml. Since the site announces its RSS location as index.xml it should be a decaying problem.
Lastly, in my original page I had some special sections that aggregated my food/recipes and software engineering topics into one page. This emulated my pre-streamlined site’s menu system. That was when it looked something like this (thank you WayBack machine for letting me reproduce it since I am, ironically, having Gem conflict problems preventing me from building that version of the site myself).
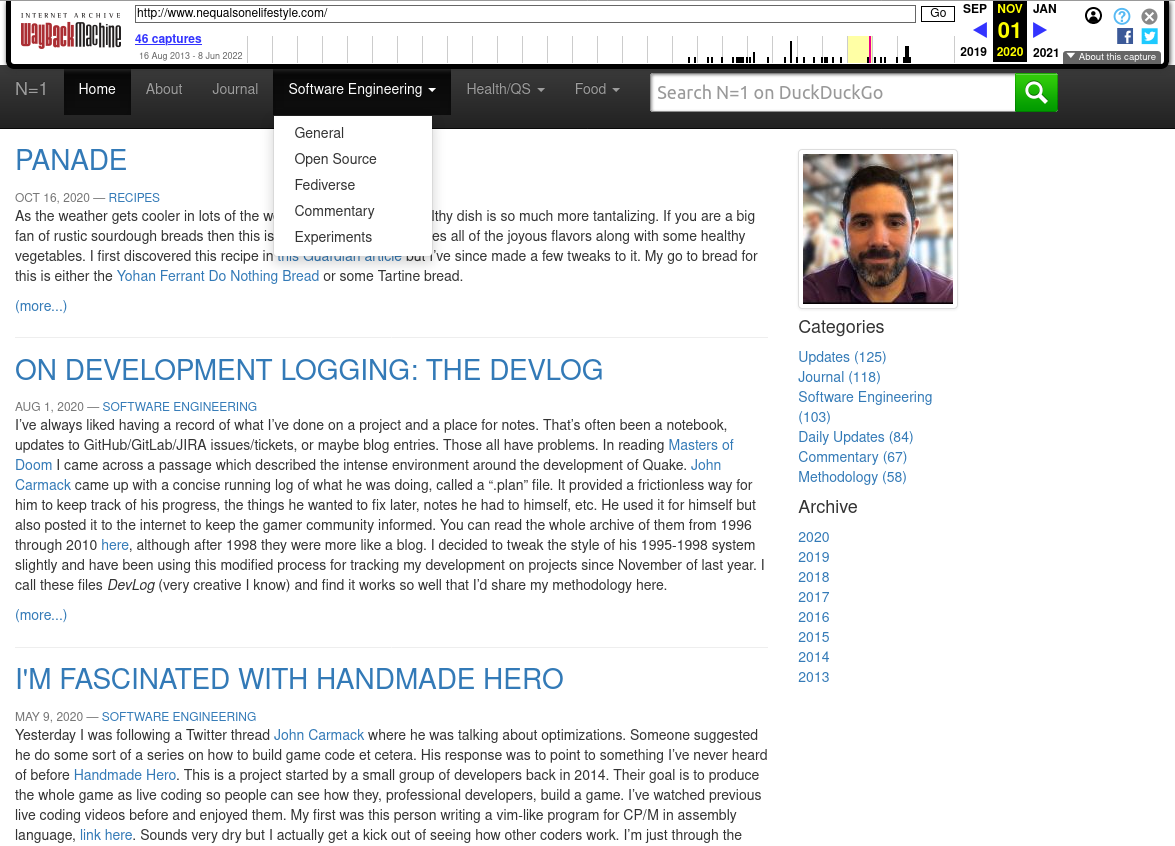
In 2018 I was trying to get into the The 512kb Club list and that website even with just text and my profile picture was well over 1 MB. For reference the current site and previous Jekyll version clock in around 75 KB with a text-only timeline. Most of the bloat was the jQuery and other JavaScript code that made the menu system and other pieces go. Since all but a few of the menus populated pages with only one or two articles it seemed a couple of subjections on the main navigation list would get me the effect I wanted. That required some pretty custom list aggregation code in Jekyll. I’d have to reproduce that in Hugo.
However it was recently pointed out to me by a friend that it was hard to navigate the page the way it was originally designed. It was ordered by type. So “Software Engineering” had all my commentary pieces, then fediverse-specific posts etc. My last Software Engineering commentary though was from 2020 so it looks like the list of articles for the whole page started in 2020. Scrolling down would finally show other sections but nothing was indicative that .at the top that there were multiple sections. A reader therefore may not know about that if they hadn’t bothered to scroll long enough. I would therefore need to fix some of the UX. However with the far better presentation style of the categories and tags in this version of the site I think those sections may be superfluous. Showing that I have both types of content at the top level could be helpful so perhaps they’ll come back in some form but not for the time being.
Site Improvements
Through this conversion not only have I relatively easily ported my site to Hugo, gotten a more streamlined build and maintenance process, and much faster build time. I also have some improvements that came along the way, mostly for free. The first, which I’ve stated several times, is build performance. Again, when I first started transitioning to static blog generators the difference between a site render time of 5 seconds and 1 second didn’t mean much to me. Now that it’s the difference between nearly a minute and a few seconds it makes a big difference. Doing things like tweaking themes don’t seem daunting to me in Hugo like it did in Jekyll either so I now not only have faster build times but easier maintenance for myself.
In terms of the site itself the first two big improvements that I like from the Hugo site is the time to read estimate in the post metadata and the automatically generated table of contents at the top. I saw that on some other sites and wanted that on my Jekyll site. Jekyll doesn’t support it out of the box but there are certainly plugins that did. Again back to the double edged sword of plugins in Jekyll it was a question of which one should I use, how stable is it, does it matter that it hasn’t been touched in six years if it still works, etc. So it never came to be. Now it is just there for free in Hugo.
Hugo automatically making the tags/categories and me just having to skin it slightly has given me a much better looking version of that. Here is what the Jekyll site categories looked like:
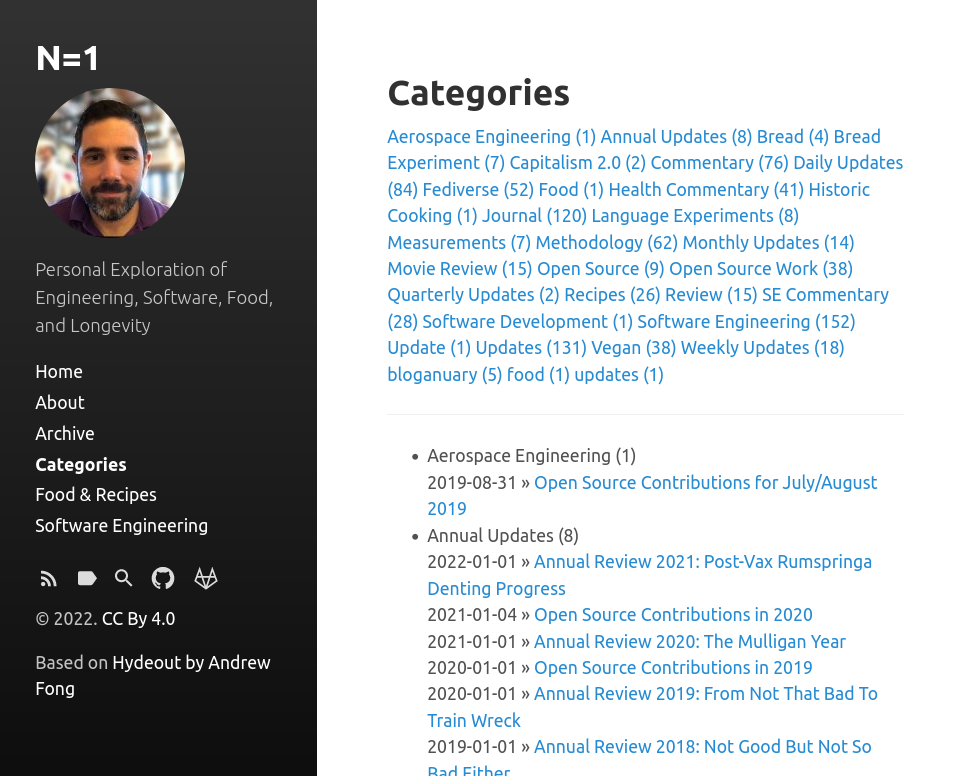
It gets the job done but I always hated how jumbled the page felt. The default one from Hugo was a big improvement:
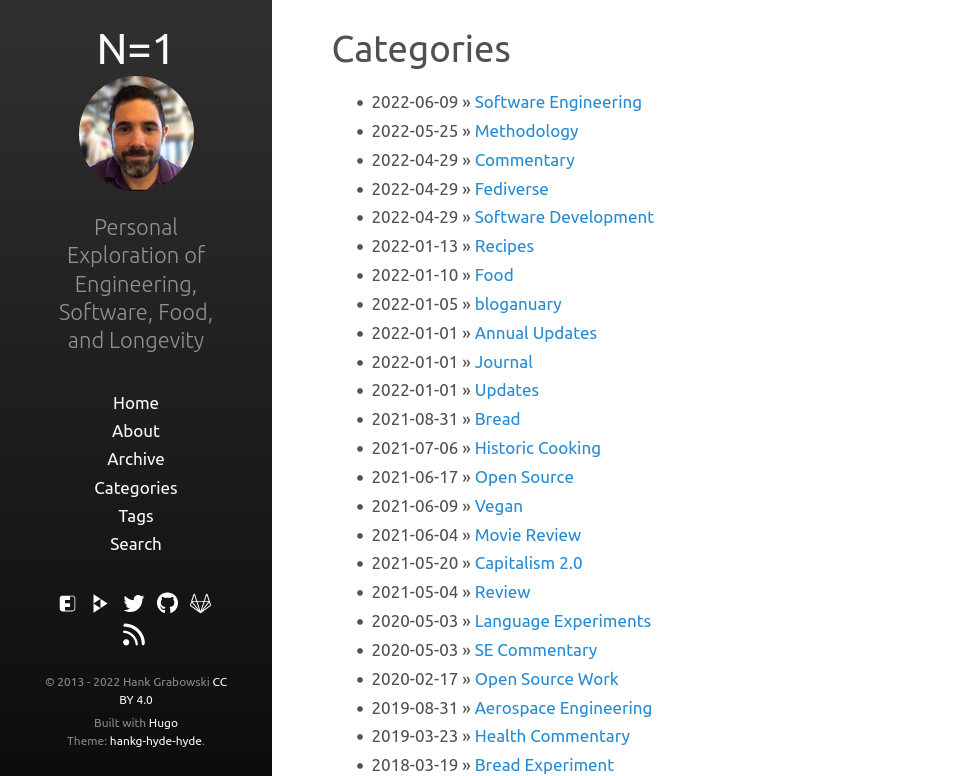
Having it sorted by reverse chronological order is actually very helpful. However I wanted to know how many posts in each category/tag there were and I wanted the list alphabetical. I found code that did this so created a custom one:
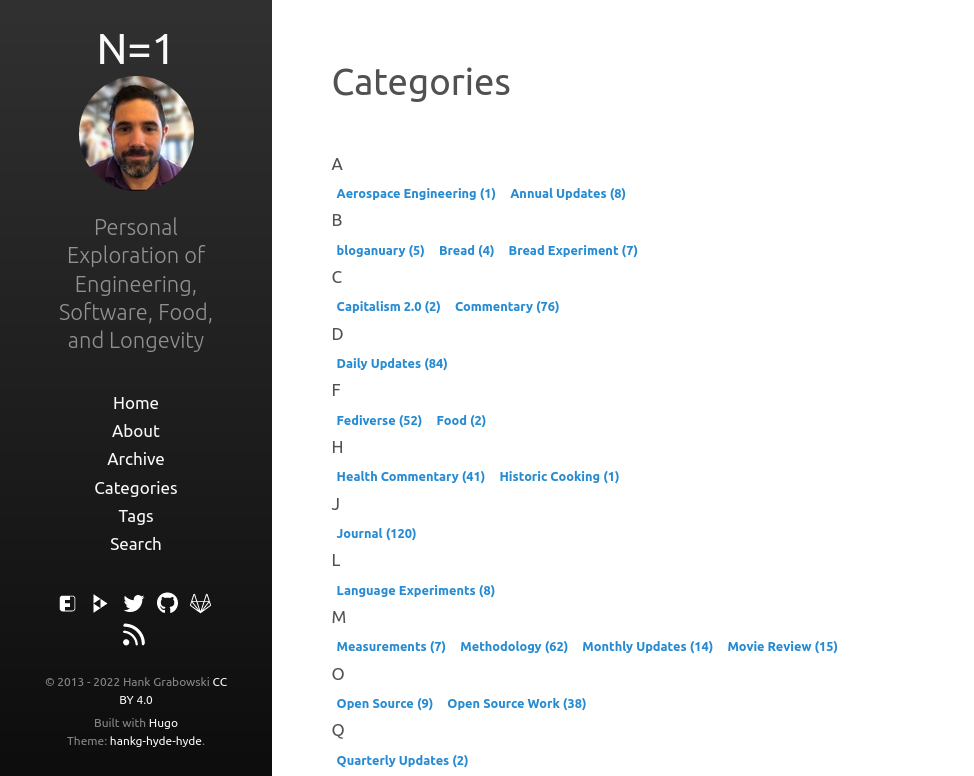
Now it is alphabetical and one can see what are popular. It’s not perfect yet and I can see the value in perhaps having it be chronological but with the count, or having the latest date next to the count, etc. This is what I’m most happy with right now though.
Lastly, by leveraging Hugo’s building of static files based on templates to build a JSON file of all the site content it is pretty easy to build a custom search block that simply pulls that JSON file (measuring it at a whopping 2 MB right now though) and some simple JavaScript. I found two articles that did similar things but went with the second one, link below, since it seemed more concise and better documented. It works better than the DDG code had been working since for some reason DDG stopped effectively indexing my site at some point. There are still some quirks with it though. I don’t like the 2MB download size so could see going back to submitting the request to DDG instead. The bigger problem is that there are obvious results that are missing. I’ll have to look at the code to see what it is doing in there. Again, it is a testament to how much intuitive the Hugo-based system is that I don’t find that daunting at all just after a couple of days. Between the better rendering of categories, tags, and search, content discovery on my site is far better than it has been for awhile on my Jekyll site.
Future steps
What are some future steps I’d like to take with the blog design? First, while I like some of the font selection stuff in the theme over my previous theme I’m not 100% thrilled with all of them. I liked my rounder, bolder, headlines over the current ones. I like the looser line spacing right now though. So I’ll probably experiment with that some.
Next, right now I’m using the old style method for handling images. Off to the side I manually create thumbnails if necessary, downsample, strip EXIF data, et cetera. They are all stored in a top level post_images folder divided by year and month. Hugo however has an entire image processing pipeline built in. It can do most of those manual steps for me automatically. It also has the concept of bundling the images with the posts which may make it easier to keep track of. Since both of those are very Hugo specific it may make transitioning to another system harder later so I want to consider it carefully. At the very least I’m going to experiment with it.
As I wrote above I like having the built in search but I’m not thrilled with the fact some obvious results don’t show up. I therefore need to see about tweaking it. It will always have the 2 MB download problem, which will increase over time as I write more. Since search isn’t something that everyone does all the time the size compromise I think I can live with that. I just want it to work better.
I may or may not add back in the sub-section stuff. The original UX didn’t cut it. If I could come up with a way for it to work better it is something I will bring back.
Lastly, and this is a big one, I got sucked down the rabbit hole on the whole aria stuff for visually impared readers. A while ago I started making sure to have meaningful ALT fields for images and not just having here for my links to other sites. I want to try to make sure the site is truly accessible to visually impared. There is a lot of technique to that though so it’s not just “throw this flag in the configuration.” As I learn more about it I’ll try to make my site easier to read for them.
Sources
- Hugo main page documentation and tutorials
- Custom formatting for tags example when learning: Germain Salvato Vallverdu’s tags page that I used to create my custom format
- Making an archive page: Thedro’s post about making archive pages
- Making a self-contained search page: Edd Turtle’s post about making your own search page in Hugo